
파이썬(python)은 웹 크롤링 기술을 사용해서 다양한 정보를 가공하여 사용자가 원하는 형태로 빠르게 변경할 수 있습니다.
웹 크롤러는 자동화된 웹페이지 탐색 기능으로 분산되어 있는 특정 정보를 확인할 수 있습니다.

파이썬(Python)에서는 웹 크롤링을 실행하기 위해서 urlopen 패키지에 포함된 urllib.request 모듈과 BeautifulSoup 패키지에 포함된 bs4 모듈을 사용합니다.

pip 기능을 사용하거나, 파이참에서 import를 실행하면 패키지를 설치할 수 있습니다.

urlopen을 사용해서 "www.daum.net" 사이트 정보를 확인합니다.
BeautifulSoup를 사용해서 "html.parser"을 실행합니다.
from urllib.request import urlopen
from bs4 import BeautifulSoup
def print_hi(name):
# Use a breakpoint in the code line below to debug your script.
print(f'Hi, {name}') # Press Ctrl+F8 to toggle the breakpoint.
# Press the green button in the gutter to run the script.
if __name__ == '__main__':
print_hi('PyCharm')
html = urlopen("http://www.daum.net")
bsObject = BeautifulSoup(html, "html.parser")
print(bsObject)

print() 함수를 사용해서 bsObject 객체를 출력하면 daum.net 전체 소스를 확인할 수 있습니다.
bsObject 객체를 사용해서 다양한 소스 접근이 가능합니다.
print(bsObject.head.title)"head.title" 사용하면 title 정보를 확인할 수 있습니다.

head에 포함된 "Daum"을 확인할 수 있습니다.
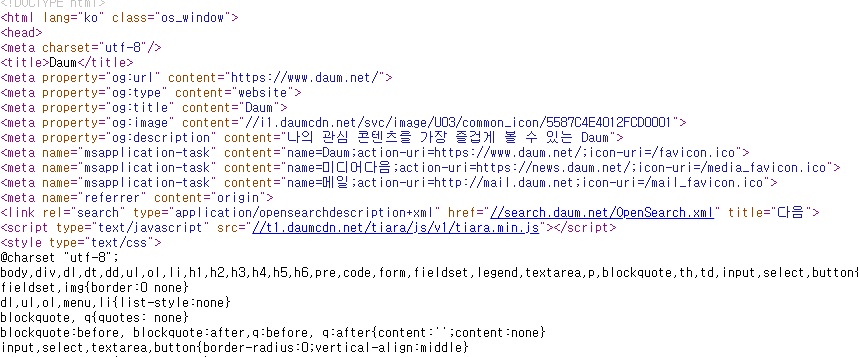
크롬에서 마우스 우클릭을 사용해서 소스보기를 실행하면 Daum 소스를 확인할 수 있습니다.
title 항목에 다양한 정보가 포함되어 있으며 항목에 따라서 웹 크롤링이 가능합니다.
이번에는 title에 포함된 content 정보를 확인해보겠습니다.
for meta in bsObject.head.find_all('meta'):
print(meta.get('content'))for 문을 사용해서 meta에 포함된 content 정보를 확인합니다.

실행 결과 소스에서 확인된 content 정보가 출력됩니다.
print(bsObject.head.find("meta", {"name": "msapplication-task"}))find 함수를 사용해서 특정 항목 전체 정보를 확인할 수 있습니다.
title 항목에서 meta 정보 중 name이 "msapplication-task"인 필드를 확인합니다.

실행 결과 name이 "msapplication-task" 최상단 정보를 확인할 수 있습니다.
마지막으로 Daum.net 메인 페이지에 포함된 모든 링크 주소를 확인하는 방법을 알아보겠습니다.
for link in bsObject.find_all('a'):
print(link.text.strip(), link.get('href'))a 항목에 href 정보를 모두 출력할 수 있습니다.

실행 결과 전체 링크 정보를 확인할 수 있습니다.
웹 크롤링을 사용하면 복잡한 웹 소스 정보 중 원하는 정보만을 가공해서 저장이 가능합니다.
저장된 정보는 다양한 함수를 사용해서 도식화할 수 있으며, 빅 데이터 활용도 가능합니다.
조금 복잡하지만 파이썬(Pytho)을 사용해서 웹 크롤링 기술을 조금씩 익혀주세요.
감사합니다.
'IT 나라 > 파이썬(python)' 카테고리의 다른 글
| [python] matplotlib을 이용한 로또 번호 파이썬 차트 그리기 (0) | 2021.06.24 |
|---|---|
| [python] 파이썬 엑셀을 활용한 로또 회차 정리하기 (0) | 2021.06.18 |
| [python] 파이썬 Tesseract OCR 활용 실습 (4) | 2021.05.25 |
| [python] 파이썬 Tesseract OCR 활용 설치하기 (0) | 2021.05.24 |
| [python] 파이썬 배열 및 리스트 (0) | 2021.04.28 |