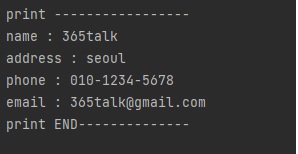
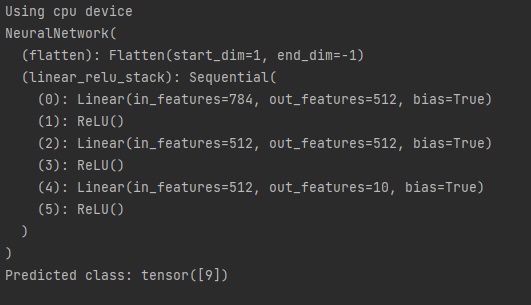
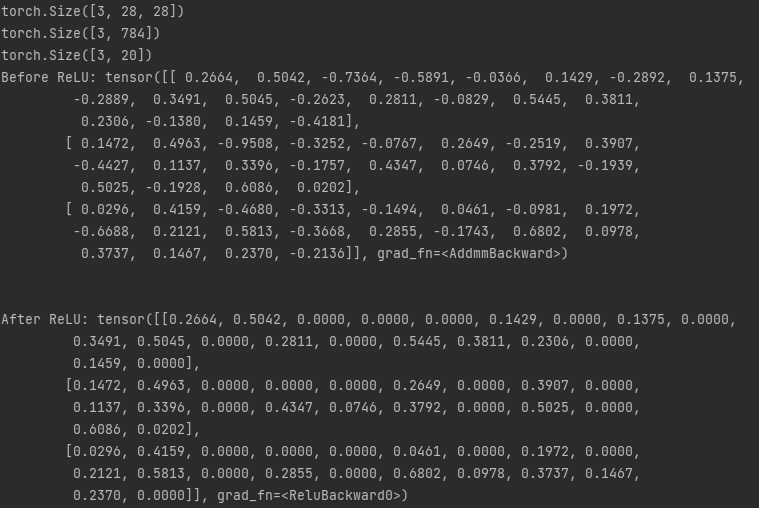
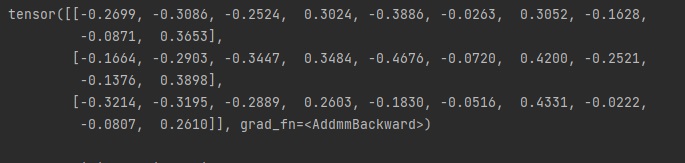
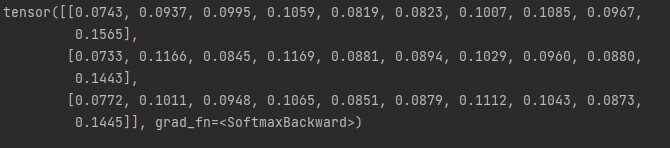
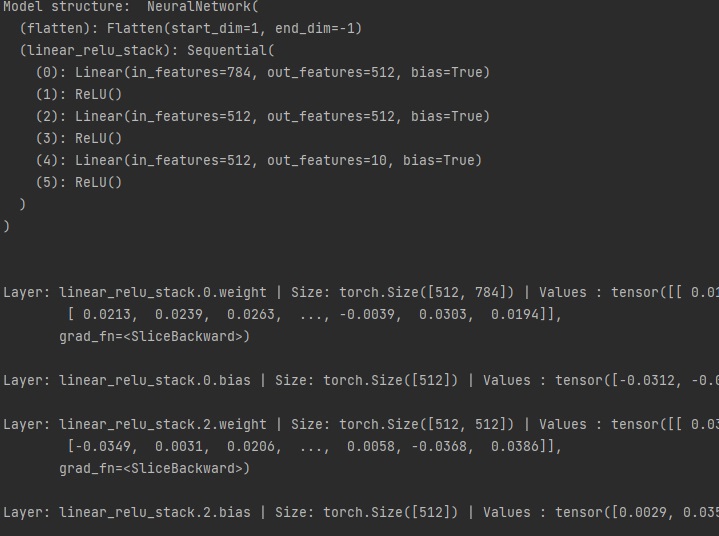
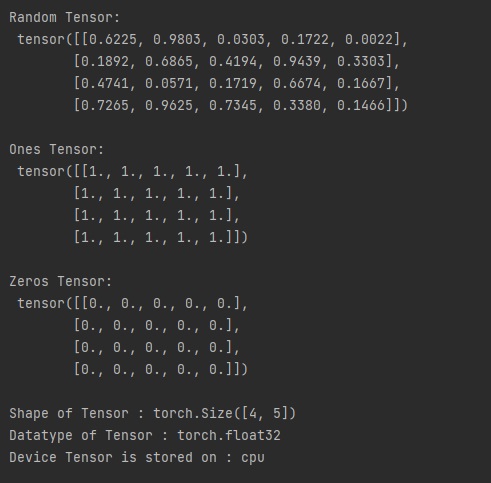
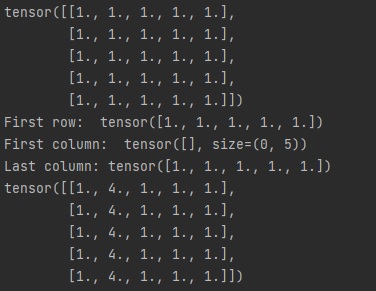
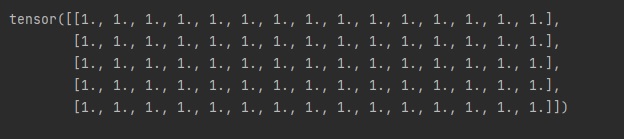
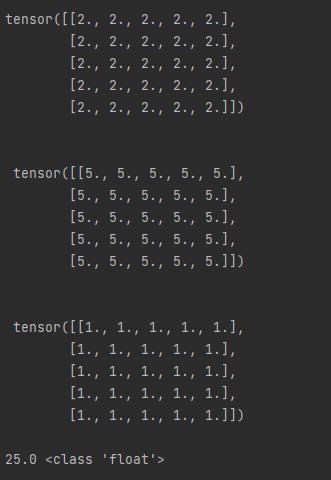
오늘은 지난 시간에 배운 matplotlib를 활용해서 여러 개의 파이썬 그래프를 그려보겠습니다.
파이썬 그래프는 다양한 타입이 있지만 오늘은 가장 많이 사용하는 막대그래프, 수평 막대그래프,
산점도 그래프, 히스토리 그래프, 차트 그래프를 알아보겠습니다.
첫 번째 파이썬 그래프는 막대그래프입니다.
matplotlib에서 bar() 함수를 사용해서 막대그래프를 확인할 수 있습니다.
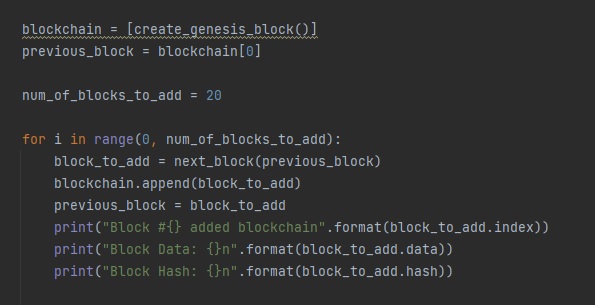
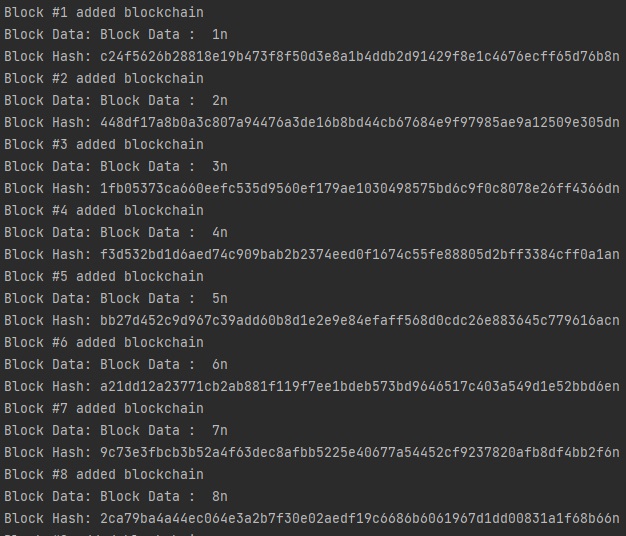
def bar():
xpos = np.arange(4)
years = ["2018", "2019", "2020", "2021"]
values = [200,300,400,500]
plt.bar(xpos, values, align='edge', color='red')
plt.xticks(xpos, years)
plt.xlabel("years")
plt.ylabel("trading volume")
plt.show()
bar() 함수를 선언해서 파이썬 막대 그래프 코드를 입력하겠습니다.
xpos 배열을 사용해서 x축 정보를 저장합니다.
x축, y축 개수가 다를 경우 오류가 발생합니다. 정확한 개수를 확인해주세요.values 배열을 사용해서 y축 정보를 저장합니다.bar() 함수에, x, y 축 정보를 입력하고 기본 옵션을 지정합니다.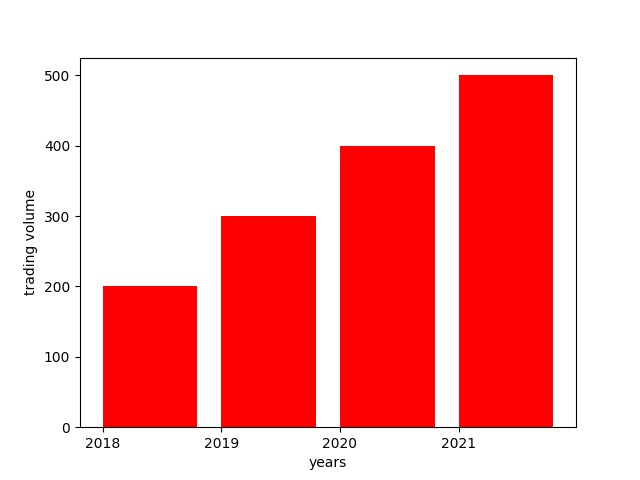
출력 결과 RED 색상 파이썬 막대그래프를 확인할 수 있습니다.
일반적으로 많이 사용되는 내용이기 때문에 그래프가 어떻게 구성되는지 감을 잡아주시면 됩니다.
두 번째는 파이썬 수평 막대 그래프를 알아보겠습니다.
matplotlib 패키지에서 barh함수를 사용해서 출력할 수 있습니다.
def barh():
ypos = np.arange(4)
years = ["2018", "2019", "2020", "2021"]
values = [200, 300, 400, 500]
plt.barh(ypos, values, tick_label=years)
plt.ylabel("trading volume")
plt.show()
barh 함수는 y축을 기준으로 정보가 동일해야 합니다.
tick_label 파라미터를 사용해서 y축 타이틀을 설정할 수 있습니다.
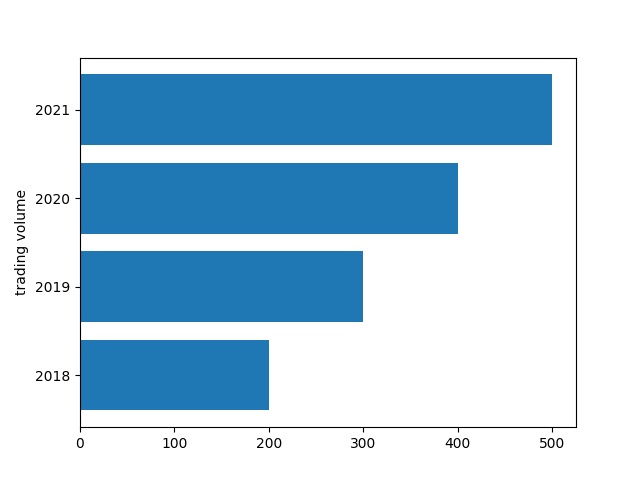
4개의 파이썬 수평 막대 그래프를 확인할 수 있습니다.
세 번째는 파이썬 산점도 그래프를 알아보겠습니다.
산점도 그래프는 x, y축 좌표에 데이터를 점으로 출력하는 그래프입니다.
분포도 사용 시 많이 사용되는 그래프입니다.
matplotlib 패키지에서 scatter() 함수를 사용해서 그래프를 그릴 수 있습니다.
def scatter():
np.random.seed(19488045)
N = 70
xpos = np.random.rand(N)
ypos = np.random.rand(N)
colors = np.random.rand(N)
area = ( 30 * np.random.rand(N))**2
plt.scatter(xpos,ypos, s=area, c=colors, alpha=0.5)
plt.show()
seed를 사용해서 랜덤 함수를 생성합니다.
seed() 함수는 0 ~ 4294967295 사이의 정수를 사용합니다.
random() 함수를 사용해서 설정된 값에 오차 범위를 지정합니다.
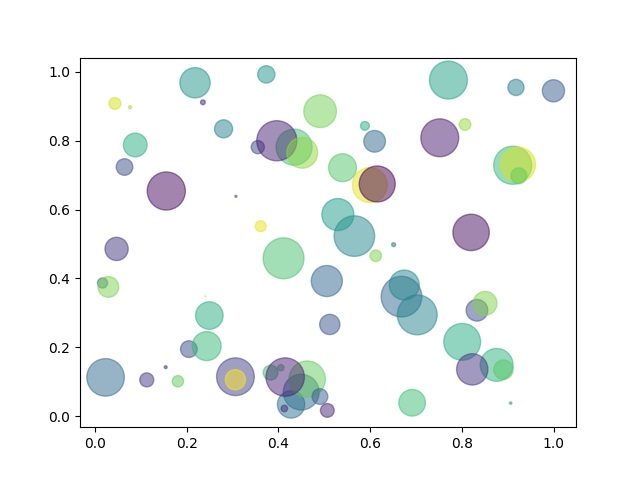
x , y 좌표에 70개의 난수 그래프가 출력됩니다.
투명도를 0.5로 지정해서 겹치는 부분까지 확인이 가능합니다.
네 번째는 파이썬 히스토리 그래프를 알아보겠습니다.
히스토리 그래프는 많은 데이터를 한눈에 보기에 좋은 그래프입니다.
구간별로 겹치지 않아 주식과 같은 차트 정보에 많이 사용되는 그래프입니다.
matplotlib에서 hist() 함수를 사용하면 히스토리 그래프를 사용할 수 있습니다.
def hist():
apos = 2.0 * np.random.rand(10000) - 1.0
bpos = np.random.standard_normal(10000)
cpos = 20.0 * np.random.rand(5000) - 10.0
dpos = 20.0 * np.random.rand(2000) - 10.0
plt.hist(apos, bins=100, density=True, alpha=0.7, histtype='step')
plt.hist(bpos, bins=50, density=True, alpha=0.5, histtype='stepfilled')
plt.hist(cpos, bins=100, density=True, alpha=0.9, histtype='step')
plt.hist(dpos, bins=50, density=True, alpha=0.5, histtype='stepfilled')
plt.show()
파이썬 히스토리 그래프는 random() 함수를 사용해서 다양한 정보를 저장할 경우 균일한 편차를 주어야 여러 개의 그래프를 비교할 수 있습니다.
편차가 다를 경우 그래프가 이동하기 때문에 전체 그래프가 작아집니다.
histtype에서 step은 막대 내부가 비어 있는 상태입니다,
stepfilled는 막대 내부가 채워진 상태입니다.
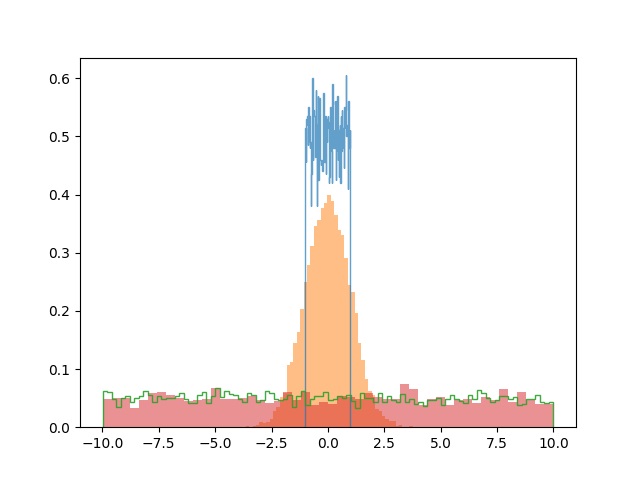
출력 결과 4개의 그래프가 다양한 형태로 출력되는 것을 확인할 수 있습니다.
마지막으로 파이썬 차트 그래프를 알아보겠습니다.
차트 그래프는 matplotlib에서 pie() 함수를 사용해서 출력할 수 있습니다.
def pie():
pos = [24, 56,12,34]
labels = ['pos1', 'pos2', 'pos3', 'pos4']
plt.pie(pos,labels=labels, autopct='%.1f%%', startangle=260, counterclock=False, shadow=True)
plt.show()
pos를 사용해서 전체 개수를 지정하고, labels로 타이틀을 설정할 수 있습니다.
autopct 파라미터를 사용해서 내부 출력 타입을 지정할 수 있습니다.
차트 그래프는 부채꼴의 중심각 비율에 비례하게 출력됩니다.
shadow 파리 미터를 사용해서 외각 그림자를 사용할 수 있습니다.

파이썬 차트 그래프는 전체 분포도를 확인할 수 있는 편리한 그래프입니다.
파이썬은 다양한 크롤링을 사용해서 그래프를 사용하는 코드가 많습니다.
간단한 함수를 사용해서 파이썬 그래프를 사용할 수 있어 초보자도 쉽게 차트 분석이 가능합니다.
위 5개의 그래프만 잘 사용해도 크롤링한 정보를 출력하기에는 부족함이 없어 보입니다.
감사합니다.
#파이썬 #그래프 #그래프타입 #python