오늘은 파이썬(python)에서 matplotlib을 사용한 차트 그리기를 알아보겠습니다.
파이썬(python) 차트를 그리기 위해서 다양한 패키지를 사용할 수 있습니다.
matplotlib 패키지는 간단하면서 다양한 차트를 출력할 수 있습니다.
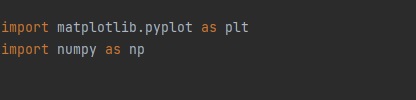
파이썬(python) 차트를 그리기 위해서 패키지를 선언해줍니다.
import matplotlib.pyplot as plt
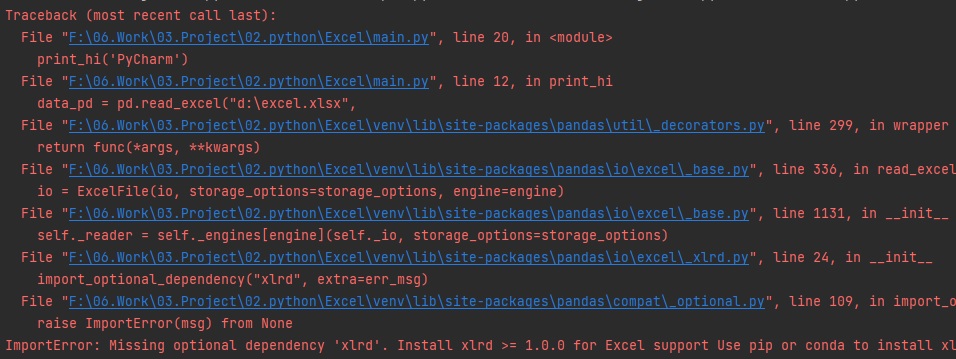
import numpy as nppip install matplotlib를 사용해서 패키지를 설치해주세요.
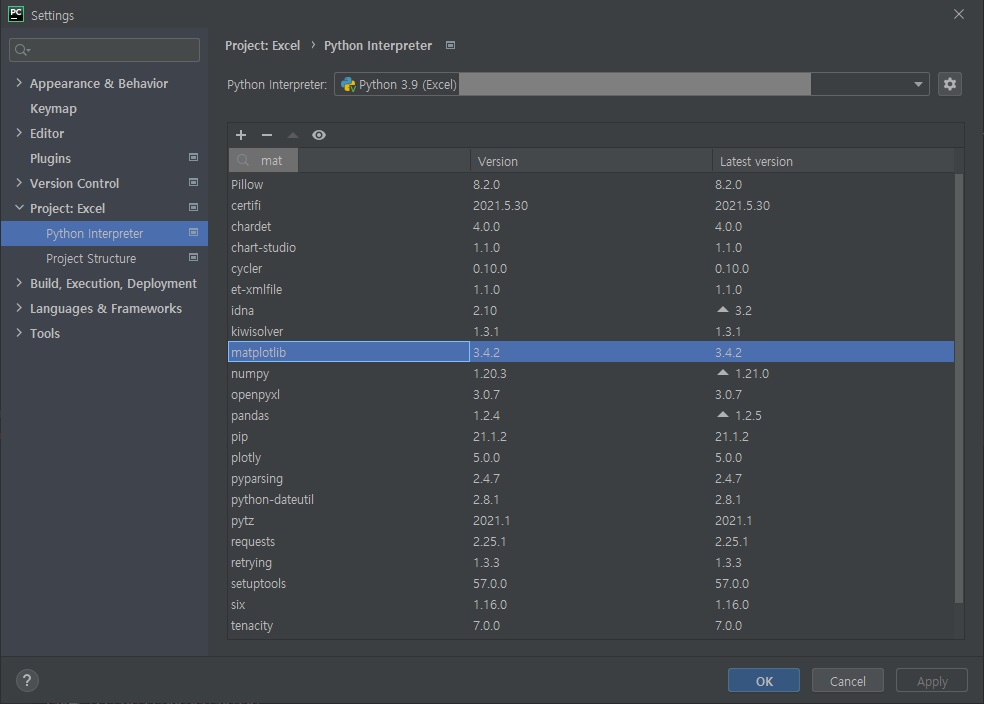
파이참을 사용할 경우 세팅에서 패키지를 검색 후 인스톨하면 됩니다.
정상적으로 인스톨되면 리스트에서 "maplotlib"를 확인할 수 있습니다.
기본적으로 차트는 x,y 좌표 정보가 필요합니다.
이번 시간에는 일반적인 차트가 아닌 로또 번호에 따른 카운트를 확인해보겠습니다.
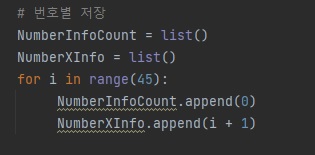
먼저 x, y에 사용할 로또 번호 정보를 저장합니다.
NumberInfoCount = list()
NumberXInfo = list()
for i in range(45):
NumberInfoCount.append(0)
NumberXInfo.append(i + 1)리스트, 배열 모두 파이썬 차트에 적용할 수 있습니다.
로또 번호는 45개 이기 때문에 45개 배열을 생성합니다.
NumberInfoCount는 y 측 value로 사용하겠습니다.
NumberXInfo는 x 측으로 1 ~ 45 번호를 적용하겠습니다.

지난 시간에 작성한 코드를 변경했습니다.
https://believecom.tistory.com/732
[python] 파이썬 엑셀을 활용한 로또 회차 정리하기
오늘은 파이썬(python)을 사용해서 엑셀파일을 사용해보겠습니다. 엑셀 파일은 다양한 정보를 순차적으로 정리할 수 있어 빅데이터 활용에 좋습니다. 엑셀 파일을 그냥 활용하기는 지루하니까 오
believecom.tistory.com
위 내용을 참고해주세요.
for i in range(len(revNumbers[0])):
line = ""
for j in range(len(revNumbers)):
value = int(revNumbers[j][i])
line += str(value) + ","
NumberInfoCount[value-1] = int(NumberInfoCount[value-1]) + 1
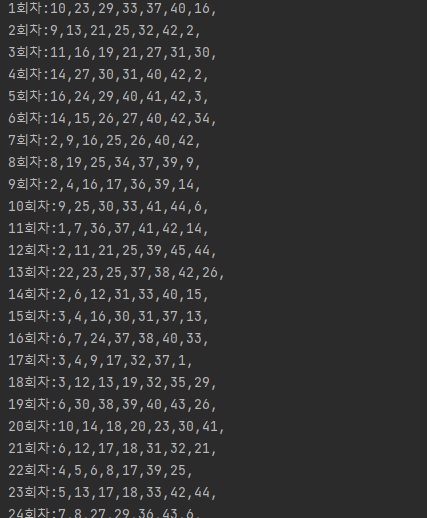
print(str(i + 1) + "회차:" + line )
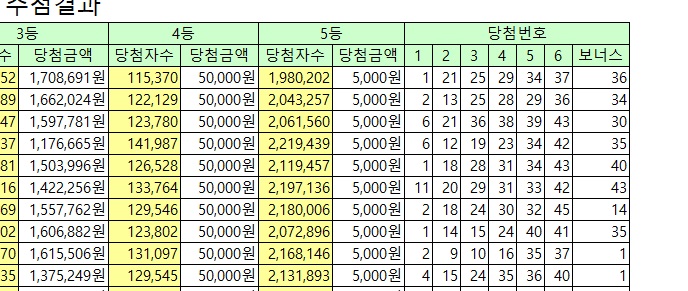
print(NumberInfoCount)1부터 45번호까지 루프를 확인하며 저장된 당첨 정보를 각 번호에 카운트하여 저장하는 로직입니다.

출력 결과 1부터 45번까지 카운트가 계산되어 배열이 저장됩니다.
이제 파이썬 차트에 사용할 x, y 모든 정보가 생성되었습니다.
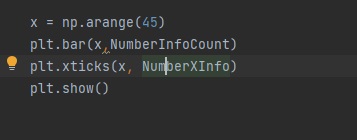
x = np.arange(45)
plt.bar(x,NumberInfoCount)
plt.xticks(x, NumberXInfo)
plt.show()np.arange()를 사용해서 파이썬 차트 x 정보를 저장합니다.
bar() 함수를 사용해서 x 측 정보를 저장합니다.
마지막으로 xticks() 함수를 사용해서 y 측 정보를 저장합니다.
show() 함수를 사용해서 파이썬 차트를 출력합니다.

출력 결과 1부터 45번까지 당첨된 횟수를 모두 확인할 수 있습니다.
966회 차 기준으로 43 번호가 가장 많이 당첨되었습니다.
파이썬(python) 차트는 4줄 코딩으로 바로 출력이 가능합니다.
일반적인 언어에서는 차트하나 개발하기가 정말 어렵지만, 파이썬(python)에서는 손쉽게 출력됩니다.
다음 시간에는 matplotlib를 이용한 다양한 차트를 알아보겠습니다.
감사합니다.
'IT 나라 > 파이썬(python)' 카테고리의 다른 글
| [python] 파이썬 그래프 타입 알아보기 (0) | 2021.07.15 |
|---|---|
| [python] 파이썬 폴더 파일 검색 및 파일 이름 변경하기 (0) | 2021.06.30 |
| [python] 파이썬 엑셀을 활용한 로또 회차 정리하기 (0) | 2021.06.18 |
| [python] 파이썬 웹 크롤링 (0) | 2021.06.11 |
| [python] 파이썬 Tesseract OCR 활용 실습 (4) | 2021.05.25 |