
크롤링 기술은 html 내용을 검색해서 다양한 정보를 빠르게 확인할 수 있는 기술입니다. 일반적으로 크롤링은 python에서 beautifulsoup를 사용해서 간단하게 html을 파싱 할 수 있어 많이 사용합니다. 오늘은 python 처럼 간편하게 HtmlAgility를 사용해서 C#에서 html 파싱 하는 방법을 알아보겠습니다.
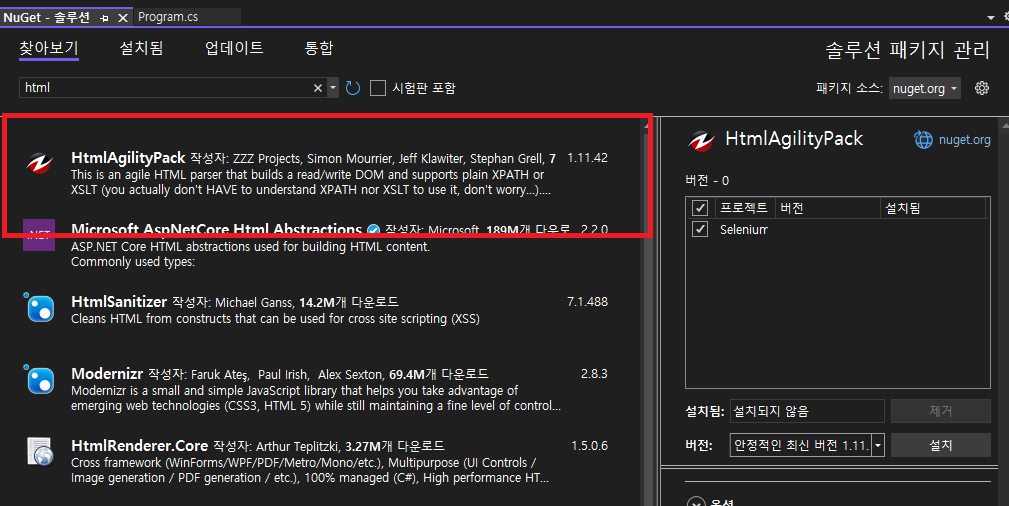
메뉴에서 Nuget 패키지 관리자를 실행하고 "HtmlAgilityPack"를 검색해주세요. 프로젝트를 선택하고 설치 버튼을 클릭하면 프로젝트에 HtmlAgilityPack이 설치됩니다.

정상적으로 설치되면 출력 내용에서 설치 경로를 확인할 수 있습니다.
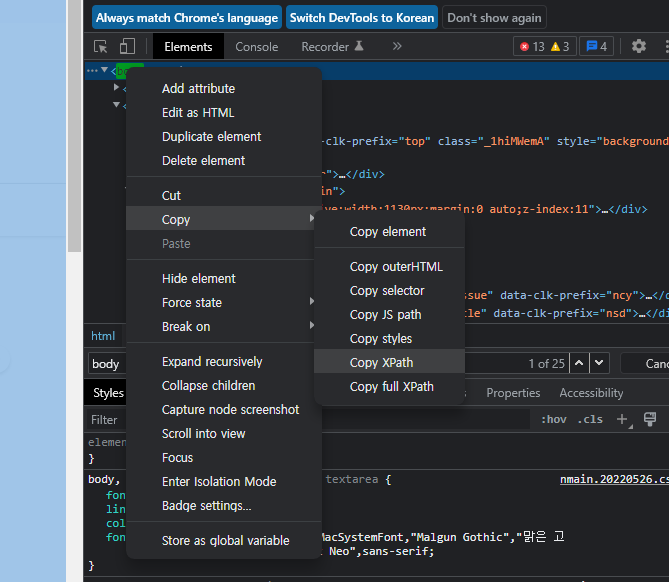
HtmlAgility를 사용하기 위해서는 기본적으로 xpath를 알아야 합니다. Chrome 브라우저에서 개발자 모드를 실행하고 크롤링하고 싶은 경로에 XPath를 저장합니다.
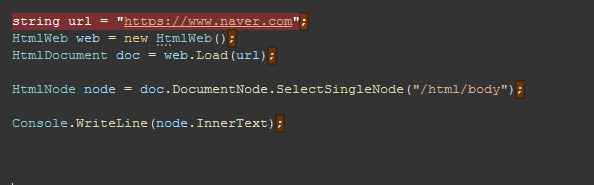
간단하게 naver.com 전체 내용을 확인하는 코드입니다.
string url = "https://www.naver.com";
HtmlWeb web = new HtmlWeb();
HtmlDocument doc = web.Load(url);
HtmlNode node = doc.DocumentNode.SelectSingleNode("/html/body");
Console.WriteLine(node.InnerText);url 설정 후 HtmlWeb 객체를 사용해서 html 내용을 확인할 수 있습니다.

출력 결과 html에서 텍스트만을 확인할 수 있습니다. 간단하게 전체 내용을 확인할 수 있어 사용하기 매우 편리합니다.
이번에는 네이버 페이지에서 모든 이미지 주소를 확인하는 코드를 작성해보겠습니다.

중복되는 정보는 SelectNodes 메서드를 사용해서 접근이 가능합니다.
HtmlNodeCollection nodes = doc.DocumentNode.SelectNodes("//img");
HtmlNode firstNode = nodes.First();
for( int i = 0; i < nodes.Count; i++)
{
Console.WriteLine(nodes[i].Attributes["src"].Value);
}처음에 저장된 doc 객체에서 Selectnodes를 사용해서 하단에 있는 모든 img 태그를 확인합니다. 최대 nodes 개수를 확인하고 Attributes를 사용해서 "src" 내용을 모두 확인할 수 있습니다.

간단한 코드를 사용해서 html에 포함된 이미지 소스 정보를 한눈에 확인할 수 있습니다. 사용법은 매우 간단하지만, 기본적으로 html 기본 구조를 알고 있어야 크롤링 기술을 사용하기 편리합니다. C#을 사용해서 간단하게 크롤링 할 수 있어 다양한 정보를 수집하기 좋습니다. python보다 C#을 좋아한다면 지금 확인해보세요.
감사합니다.

'IT 나라 > C#' 카테고리의 다른 글
| C# 관리자 권한 실행 방법 알아보자 (0) | 2022.07.25 |
|---|---|
| C# 셀레니움(selenium)을 이용한 ChromeDriver 사용방법 (0) | 2022.06.01 |
| C# ML.NET 사용한 머신 러닝 값 예측 (0) | 2022.05.11 |
| C# ML.NET 사용한 머신 러닝 Data Classification (0) | 2022.04.28 |