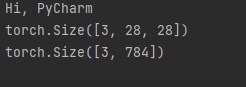
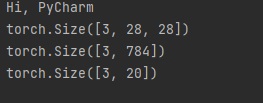
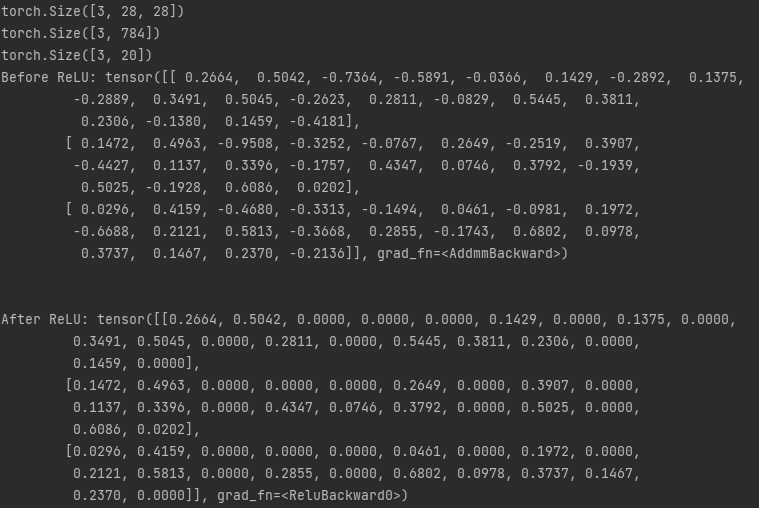
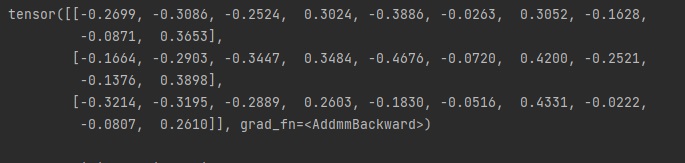
오늘은 파이썬(Python) 파이토치(PyTorch)에서 자연어를
처리하기 위해서 우선적으로 해야 할 토큰 만들기를 알아보겠습니다.
자연어를 처리하기 위해서는 단어를 구분해서
문장을 해석해야 합니다.
간단하게 문장과 공백으로도 나눌 수 있지만
정확한 의미를 확인하기 위해서는 문장과 공백만을
구분해서는 사용하기 힘듭니다.
NLP 작업에 사용되는 말뭉치(corpus)는 원시 텍스트와
메타데이터로 구성됩니다.
원시 텍스트, 메타데이터를 구분하기 위해서
오픈 소스 NLP 패키지는 대부분 코큰화 기능을 지원합니다.
대표적인 NLP 두가지 제품을 사용해서 토큰화를 확인해보겠습니다.
첫 번째 오픈 NLP 패키지 spacy
spaCy · Industrial-strength Natural Language Processing in Python
spaCy is a free open-source library for Natural Language Processing in Python. It features NER, POS tagging, dependency parsing, word vectors and more.
spacy.io
spacy를 사용하기 위해서는 먼저 패키지를 설정해야 합니다.
spacy는 패키지 설치 시간이 조금 오래 걸립니다.

import spacyimport를 사용해서 spacy 패키지를 로드합니다.
def spacyex():
nlp = spacy.load('en_core_web_sm')
# Process whole documents
text = ("When Sebastian Thrun started working on self-driving cars at "
"Google in 2007, few people outside of the company took him "
"seriously. “I can tell you very senior CEOs of major American "
"car companies would shake my hand and turn away because I wasn’t "
"worth talking to,” said Thrun, in an interview with Recode earlier "
"this week.")
doc = nlp(text)
# Analyze syntax
print("Noun phrases:", [chunk.text for chunk in doc.noun_chunks])
print("Verbs:", [token.lemma_ for token in doc if token.pos_ == "VERB"])
# Find named entities, phrases and concepts
for entity in doc.ents:
print(entity.text, entity.label_)spacy.load() 함수를 사용해서 core를 로드합니다.
text에 일반 문장으로 입력합니다.
nlp를 사용해서 토큰화를 진행합니다.

출력 결과 일반 문장을 토큰화 하여 출력합니다.
token.pos_를 사용하면 단어를 분류하여
품사 태깅을 확인할 수 있습니다.
혹 spacy를 사용 중 오류가 발생하면 아래 내용을 참고해주세요.
https://believecom.tistory.com/746
python spacy 모델 사용 중 Can't find model 'en_core_web_sm'. It doesn't seem to be a Python package 오류 처리 하기
python 자연어 처리를 공부하면서 spacy모델을 사용한 기본 테스트를 하게 되면 오류가 발생합니다. 오류 내용은 "Can't find model 'en_core_web_sm'. It doesn't seem to be a Python package" 입니다. 모델이..
believecom.tistory.com
두 번째 오픈 NLP 패키지 nltk
Natural Language Toolkit — NLTK 3.6.2 documentation
Natural Language Toolkit NLTK is a leading platform for building Python programs to work with human language data. It provides easy-to-use interfaces to over 50 corpora and lexical resources such as WordNet, along with a suite of text processing libraries
www.nltk.org

nltk 패키지도 import를 사용해서 설치가 가능합니다.
nltk는 패키지 다운로드 후 컴파일을 진행하면
추가 패키지를 다운로드해야 합니다.
nltk.download() 함수를 사용해서 오류 발생 시
패키지를 하나씩 선택하면 됩니다.
def nltkex():
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')
nltk.download('maxent_ne_chunker')
nltk.download('words')
nltk.download('treebank')
sentence = """At eight o'clock on Thursday morning Arthur didn't feel very good."""
tokens =nltk.word_tokenize(sentence)
print(tokens)
tagged = nltk.pos_tag(tokens)
print(tagged[0:6])
eltities = nltk.chunk.ne_chunk(tagged)
print(eltities)
t = treebank.parsed_sents('wsj_0001.mrg')[0]
t.draw()nltk.word_tokenize() 함수를 사용해서 토큰화를 진행합니다.
nltk.pos_tag()함수는 품사 태깅을 진행 후
토큰 정보를 출력할 수 있습니다.

간단한 함수 사용으로 토큰화를 진행할 수 있습니다.

청크 나구기를 하기 위해서는 nltk.chunk.ne_chunk() 함수를 사용합니다.
간단한 출력으로 문장의 청크를 구분할 수 있습니다.

파이토치(PyTorch) 자연어 처리에서 토큰, 청크 단위로 문장을
구분하면 정확한 구조를 확인하기 위해서 트리구조가 가장 좋습니다.
nltk 패키지에서는 treebank를 사용해서 트리구조
내용을 확인할 수 있습니다.
자연어 처리에서 문장을 처리하기 위한
토큰화는 가장 기본되는 작업입니다.
두 가지 오픈 패키지를 사용해서 우선적인 자연어 처리
기본을 공부하면 좋겠습니다.
감사합니다.
'IT 나라 > 파이썬(python)' 카테고리의 다른 글
| [python] 파이썬 제어문 반복문 활용하기 (0) | 2022.03.21 |
|---|---|
| [python] 파이썬 주석 달기 (0) | 2022.03.18 |
| python spacy 모델 사용 중 Can't find model 'en_core_web_sm'. It doesn't seem to be a Python package 오류 처리 하기 (0) | 2021.09.01 |
| [python] 파이썬 다른 py 스크립트 실행하기 (1) | 2021.08.28 |
| [python] 파이썬 블록 체인 시작 (0) | 2021.08.11 |