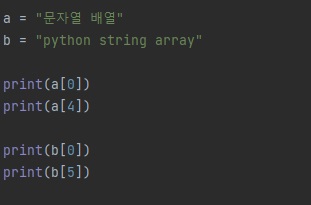
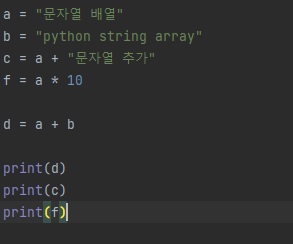
파이썬(python)은 복잡한 코드도 간단하게 코딩할 수 있는 정말 좋은 프로그램 언어입니다.
파이썬을 사용하면 인터 프린터 형태로 컴파일되기 때문에 한 개의 변수 형태로 많이 사용합니다.
간단한 코드는 다양한 변수를 사용해소 코드가 가능하지만, 조금씩 변수가 증가하면 매우 복잡해지겠죠.
먼저 간단하게 이름, 주소, 전화 번호를 출력하는 프로그램을 작성해보겠습니다.
def printInfo():
name = "365talk"
address = "seoul"
phone = "010-1234-5678"
print(f"name : {name}")
print(f"address : {address}")
print(f"phone : {phone} ")name, address, phone 변수를 선언 후 정보를 저장합니다.
print() 함수를 사용해서 변수를 출력합니다.
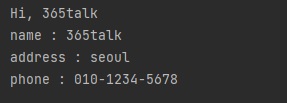
name, address, phone 모든 내용을 한 번에 확인할 수 있습니다.
그럼 이번에는 변수 한개를 더 추가해보겠습니다.
email 변수를 사용해서 mail 정보를 입력합니다.
def printInfo():
name = "365talk"
address = "seoul"
phone = "010-1234-5678"
email = "365talk@gmail.com"
print(f"name : {name}")
print(f"address : {address}")
print(f"phone : {phone} ")
print(f"email : {email}")email 변수 추가와 동시에 출력하기 위한 print() 정보도 추가합니다.
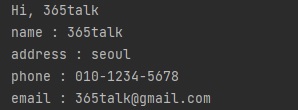
출력 결과도 동일하게 print()함수를 사용해서 출력할 수 있습니다.
간단한 변수를 여러개 사용할 경우 추가적으로 변수를 선언하면 됩니다.
하지만 변수 개수가 증가할수록 코드 길이가 길어지면서 관리하기가 점점 힘들어집니다.
변수를 혹 배열로 사용할 경우는 변수 관리는 더욱더 복잡해집니다.
클래스 구조
파이썬(python)은 이러한 관리 문제를 해결하기 위해서 클래스(Class)를 사용할 수 있습니다.

클래스(Class)는 간단하게 말하면 변수 그룹, 함수 그룹을 모두 하나의 그룹으로 관리할 수 있는 집합 객체입니다.
클래스(Class)를 사용하면 객체를 복사할 수 있기 때문에 배열에 사용하기도 매우 편리합니다.
파이썬(python)에서는 함수와 동일하게 class를 단어를 앞쪽에 선언해서 클래스(Class)를 선언할 수 있습니다.
class DataInfo:
pass
info = DataInfo()
print(info)
print(type(info))class DataInfo 객체를 생성했습니다.
DataInfo 객체를 생성하고 출력하면 객체가 생성된 주소 정보를 확인할 수 있습니다.

DataInfo 객체 시작 주소 정보는 0x00001FDA308F7C0 입니다.
DataInfo 클래스에 추가되는 함수, 변수 모두 주소 이후 연속으로 메모리에 할당됩니다.
type() 함수를 사용하면 생성한 클래스(Class) 타입도 확인이 가능합니다.
클래스 만들기
처음에 코딩한 변수 출력 부분을 클래스(Class)로 변경해보겠습니다.
class DataInfo:
def set_DataInfo(self, name, address, phone, email):
self.name = name
self.address = address
self.phone = phone
self.email = email
def print(self):
print(f"print -----------------")
print(f"name : {self.name}")
print(f"address : {self.address}")
print(f"phone : {self.phone} ")
print(f"email : {self.email}")
print(f"print END--------------")파이썬(python)에서 클래스(Class)를 사용하기 위해서는 메서드앞에 self를 반드시 추가해야 합니다.
self는 클래스(Class)에 생성되는 모든 메서드에 포함되어야 합니다.
set_DataInfo() 메서드 사용 시 self에 name, address, phone, email 변수를 선언하고 인자를 저장합니다.
self에 저장된 변수는 print() 함수를 이용해서 각 변수에 접근 후 출력이 가능합니다.
name = "365talk"
address = "seoul"
phone = "010-1234-5678"
email = "365talk@gmail.com"
info = DataInfo()
info.set_DataInfo(name, address, phone, email)
info.print()info 변수에 DataInfo() 클래스를 할당합니다.
set_DataInfo() 메서드를 사용해서 name, address, phone, email 정보를 저장할 수 있습니다.
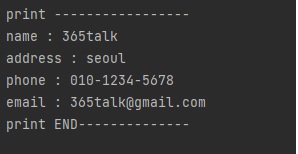
클래스(Class) 객체 선언 후 간단하게 print() 메소드를 사용해서 모든 정보를 출력할 수 있습니다.
파이썬(phthon)에서 클래스(Class)를 사용하게 되면 모든 메서드에 self 인자를 무조건 처음에 사용해야 합니다.
self를 사용하지 않으면 컴파일 과정에서 오류가 발생합니다.
파이썬(phthon)에 사용되는 self 인자는 클래스(Class) 내부 인스턴스 객체로 초기 설정값을 저장하고 인스턴스 형태로 접근이 가능합니다.
즉 인스턴스 형태 메서드를 사용하던, 클래스 형태 메서드를 사용하던 모두 하나의 주소 정보에 접근합니다.
조금 어려운 부분이지만, 그냥 간단하게 객체를 관리하는 집주인이라고 생각하시면 됩니다.
클래스 초기화 __init__ 메서드
파이썬(phthon) 클래스(Class)에서도 생성자를 사용한 초기화가 가능합니다.
class DataInfo:
def __init__(self, id):
self.id = id
print("Class Init")
def set_DataInfo(self, name, address, phone, email):
self.name = name
self.address = address
self.phone = phone
self.email = email
def print(self):
print(f"print -----------------")
print(f"name : {self.name}")
print(f"address : {self.address}")
print(f"phone : {self.phone} ")
print(f"email : {self.email}")
print(f"id : {self.id}")
print(f"print END--------------")생성된 클래스(Class)에서 __init___ 메서드를 사용해서 초기화가 가능합니다.
__init__ 메서드는 객체가 처음 생성되는 시점에 무조건 호출됩니다.
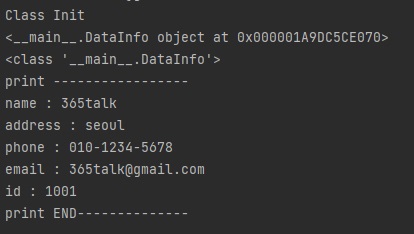
DataInfo 객체를 선언하는 시점에 __init__에 코딩한 print() 함수가 호출되는 것을 확인할 수 있습니다.
파이썬(python) 클래스(Class)에 미리 선언된 메서드는 "__이름__" 형태로 선언되어 있습니다.
파이참을 사용할 경우 메서드를 바로 확인할 수 있기 때문에 다양한 메서드를 확인해보세요.
파이썬(python) 클래스(Class)는 다양한 API 객체로 배포되기 때문에 꼭 알아야 하는 개념입니다.
클래스(Class) 사용 개념이 없을 경우 크롤링, 주식 API 등 복잡한 코드에 접근하기 어렵습니다.
오늘도 열심히 파이썬(Python) 공부하세요.
감사합니다.

'IT 나라 > 파이썬(python)' 카테고리의 다른 글
| [python] 파이썬 다른 py 스크립트 실행하기 (1) | 2021.08.28 |
|---|---|
| [python] 파이썬 블록 체인 시작 (0) | 2021.08.11 |
| [python] 파이썬 파이토치 신경망 활용하기 (0) | 2021.07.23 |
| [python] 파이썬 파이토치 데이터 세트 활용하기 (0) | 2021.07.22 |
| [python] 파이썬 파이토치 Tensor 사용법 (0) | 2021.07.17 |