사이트 정보를 가져오기 위해서는 다양한 기술을 사용할 수 있습니다. 파이썬(python)에서는 Requests를 사용해서 사이트 정보를 가져올 수 있습니다. 간단하게 설치 후 사용할 수 있어 매우 편리하게 WEB 정보를 확인할 수 있어 크롤링에 많이 사용됩니다.
먼저 requests를 설치해야 합니다. pip 명령어를 사용해서 requests를 install 해주세요.

처음 설치하면 정상적으로 설치됩니다. 전 이전에 설치되어 있어 오류 메시지가 출력되었습니다.
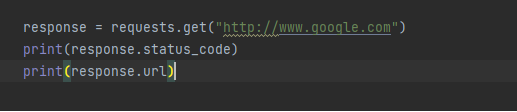
requests는 간단하게 get 메서드를 사용해서 사이트 정보를 확인할 수 있습니다. get 메서드에 사이트 정보를 입력합니다. status_code를 확인하면 정상적인 상태 사이트 확인이 가능합니다.

출력 결과 200 코드를 확인할 수 있습니다.
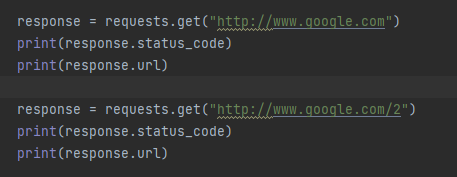
사이트 정보를 확인할 수 없는 내용을 사용할 경우 404 오류 코드를 리턴합니다.
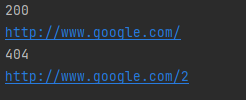
출력 결과 404 에러를 확인할 수 있습니다. 처음 사이트 정상 유무를 먼저 확인하고 사이트 텍스트를 확인하는 게 가장 좋은 방법입니다.
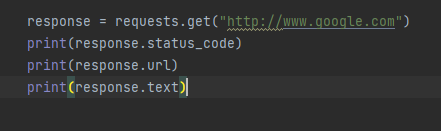
text 속성을 사용하면 UTF-8로 인코딩된 사이트 텍스트 정보를 확인할 수 있습니다.

개발자 모드로 확인할 수 있는 사이트 HTML 정보를 한 번에 확인할 수 있습니다. 그런데 모든 코드가 포함되어 매우 복잡한 구조입니다.
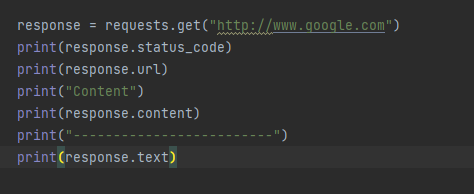
content 속성을 사용하면를 바이너리 타입으로 변경되어 쉽게 사이트 텍스트 확인 가능합니다.
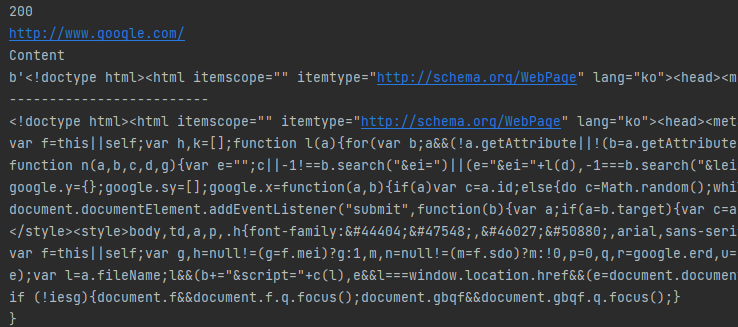
text 속성과 비교하면 매우 간결한 내용을 확인할 수 있습니다. 파이썬(python) requests 객체는 사이트 정보를 확인해서 다양한 정보를 빠르게 추출할 수 있어 매우 편리합니다. 간단한 속성으로 사용으로 빠르게 사이트 접근이 가능해서 WEB 자동화 프로그램을 개발할 때 꼭 필요한 객체입니다.
감사합니다.

'IT 나라 > 파이썬(python)' 카테고리의 다른 글
| [python] 파이썬 IntelliJ Python 프로젝트 환경 설정 방법 (0) | 2023.01.18 |
|---|---|
| [python] 파이썬 Requests를 사용해서 GET 및 POST 메시지 전송하기 (0) | 2022.06.22 |
| [python] 파이썬 ChromeDriver DeprecationWarning find_element_by_xpath is deprecated 오류 (1) | 2022.05.28 |
| [python] 파이썬 ChromeDriver and selenium을 이용한 매크로 만들기 (0) | 2022.05.18 |
| [python] 파이썬 버전 PyCharm에서 변경 하기 (0) | 2022.03.25 |