react native는 android, iOS를 동시게 개발할 수 있는 장점이 있습니다. 동시에 두 가지 디바이스를 적용할 수 있어 생산성이 정말 최고입니다. 오늘은 Windows 환경에서 react native 설치 및 실행 방법을 알아보겠습니다.
Chocolatey 설치
가장 먼저 Windows 환경에서 패키지를 설치할 수 있는 Chocolatey를 설치해주세요. 간단하게 다양한 패키지를 설치할 수 있는 좋은 프로그램입니다.
cmd 환경에서 아래 명령어를 입력해서 설치하면 됩니다.
@"%SystemRoot%\System32\WindowsPowerShell\v1.0\powershell.exe" -NoProfile -InputFormat None -ExecutionPolicy Bypass -Command "iex ((New-Object System.Net.WebClient).DownloadString('https://chocolatey.org/install.ps1'))" && SET "PATH=%PATH%;%ALLUSERSPROFILE%\chocolatey\bin"명령어를 입력하면 자동으로 다운로드 후 설치가 진행됩니다.

choco -v를 사용해서 chocolatey 버전을 확인할 수 있습니다.
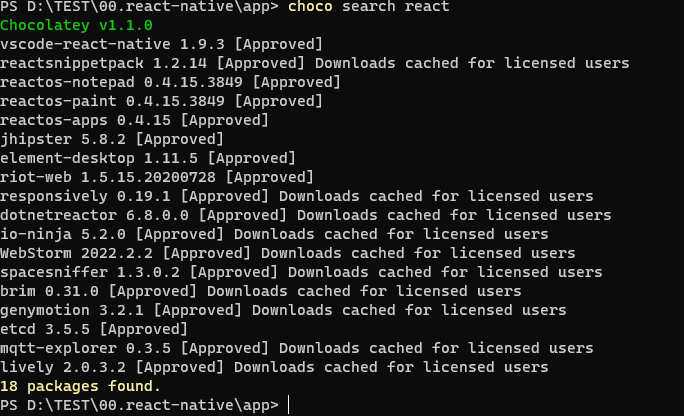
choco search 패키지를 입력하면 내용을 확인할 수 있습니다.
Nodejs 설치
react-native는 javascript를 사용하므로, javascript의 런타임 Nodejs를 설치해야 합니다. 기본적으로 개발환경이 구성되어 있다면 간단하게 버전 확인 후 설치 안되어 있다면 choco 명령어를 사용해서 설치합니다.
choco install -y nodejs.install

정상적으로 nodejs가 설치되어 있다면 node -v 명령어를 사용해서 버전을 확인할 수 있습니다.
react-native CLI 설치
이제 react-native를 실행할 수 있는 react-native CLI를 설치해야 합니다.

npm install -g react-native-cli 명령어를 사용해서 react-native-cli를 설치합니다.

정상적으로 설치되었다면 npx react-native -v 명령어를 사용해서 버전을 확인할 수 있습니다.
react-native project 생성
react-native-cli이 정상적으로 설치되어 있다면 이제 react-native project를 생성해서 android 버전을 확인해야 합니다.
npx react-native init app2
react-native init 명령어를 사용해서 프로젝트를 생성합니다.

혹 실행 시 react 심벌이 아닌 텍스트 warning이 화면에서 보일 경우는 비정상적으로 react-native가 설치된 상태입니다.
https://believecom.tistory.com/781
react native error cli.init is not a function 해결 방법
react native를 설치 후 프로젝트를 생성할 경우 정상적으로 react 화면이 출력되어야 합니다. 하지만 비정상적으로 react native가 설치되면 "cli.init is not a function" 오류가 발생합니다. 다양한 방법을..
believecom.tistory.com
위 내용을 참고해서 react-native를 재 설치하면 정상적으로 프로젝트를 생성할 수 있습니다.
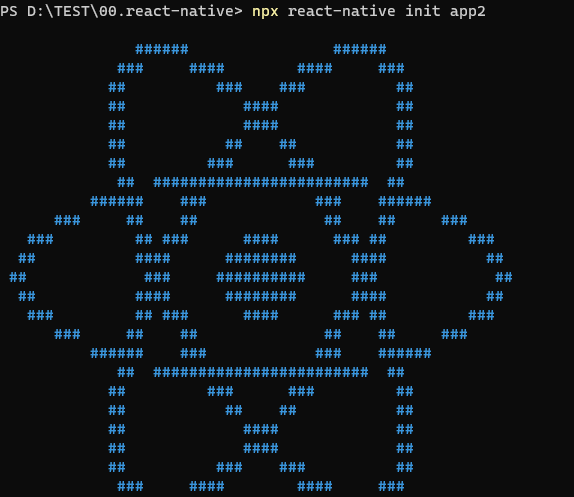
정상적으로 프로젝트가 설치되면 react-native 심벌 이미지를 확인할 수 있습니다.
Visual Studio Code 설치
이제 생성된 소스를 확인하기 위해서 가장 간편하고 쉽게 사용할 수 있는 Visual Studio Code를 설치합니다.
https://visualstudio.microsoft.com/ko/downloads
Visual Studio Tools 다운로드 - Windows, Mac, Linux용 무료 설치
Visual Studio IDE 또는 VS Code를 무료로 다운로드하세요. Windows 또는 Mac에서 Visual Studio Professional 또는 Enterprise Edition을 사용해 보세요.
visualstudio.microsoft.com
하단에서 Visual Studio Code를 다운받아서 설치해주세요.
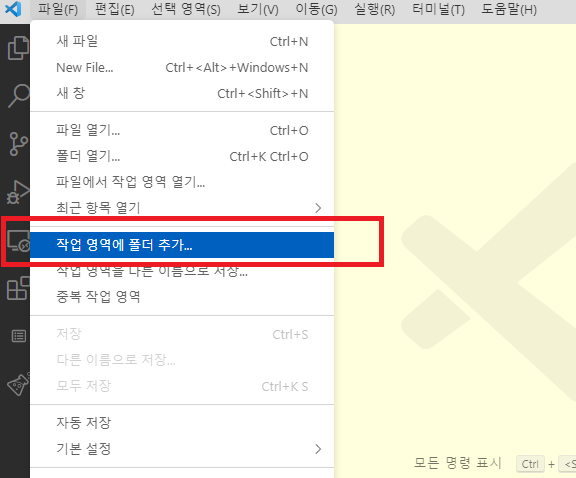
Visual Studio Code 설치 후 실행하면 파일 메뉴에서 "작업 영역에 폴더 추가"를 사용해서 생성된 react-native 프로젝트 폴더를 선택합니다.
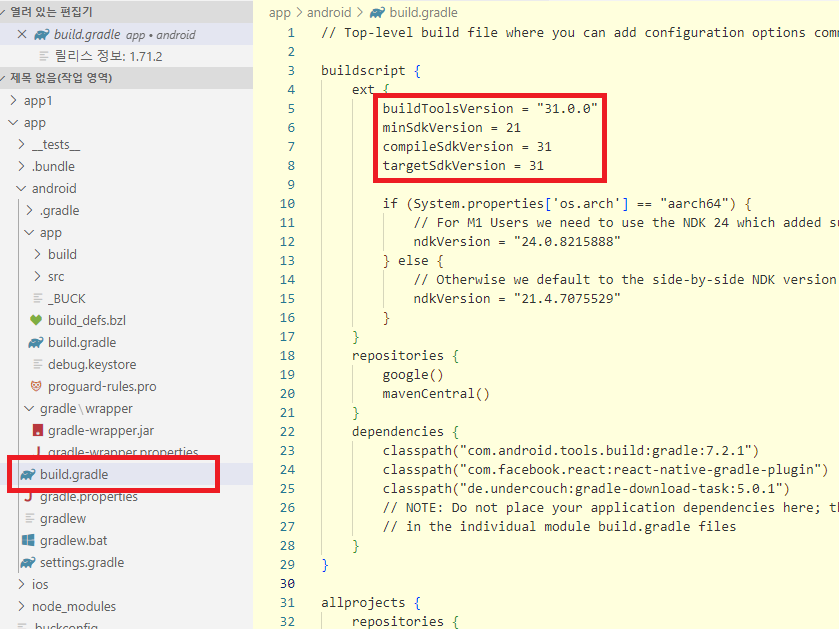
android 폴더 하단에 있는 build.gradle 파일을 오픈해서 android 실행 버전을 확인합니다. buildToolsVersion 버전이 31 버전으로 실행되는 것을 확인할 수 있습니다. Visual Studio Code를 사용하면 쉽게 코드를 수정할 수 있어 매우 편리합니다. 가장 좋은 점은 iOS에서도 사용이 가능하고 다양한 plug in을 사용할 수 있습니다. 이제 버전을 확인했으니, android SDK를 설치해야 합니다.
Android SDK 설치
Android SDK를 설치하기 위해서 android Studio를 다운로드 후 설치해주세요.
https://developer.android.com/studio?hl=ko
Download Android Studio & App Tools - Android Developers
Android Studio provides app builders with an integrated development environment (IDE) optimized for Android apps. Download Android Studio today.
developer.android.com
android Studio 설치 후 File -> Setting 메뉴를 선택해서 android SDK를 확인합니다.

Android API 31버전을 체크해서 SDK를 설치합니다.
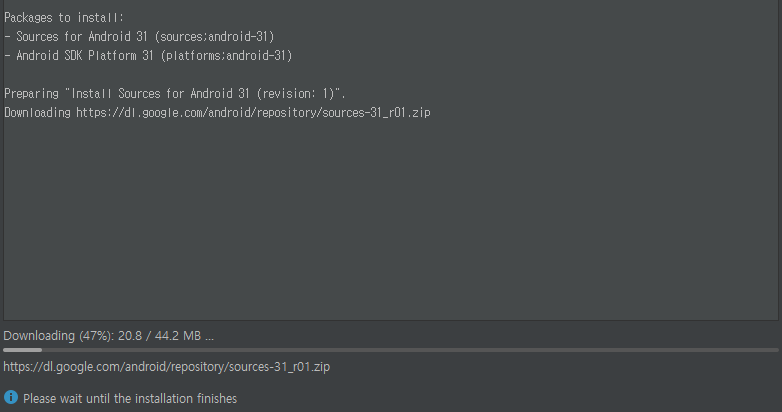
정상적으로 설치되면 SDK 폴더에서 android 31 버전을 확인할 수 있습니다. 이제 AVD Manager를 사용해서 android 31 버전 Devices를 생성합니다.
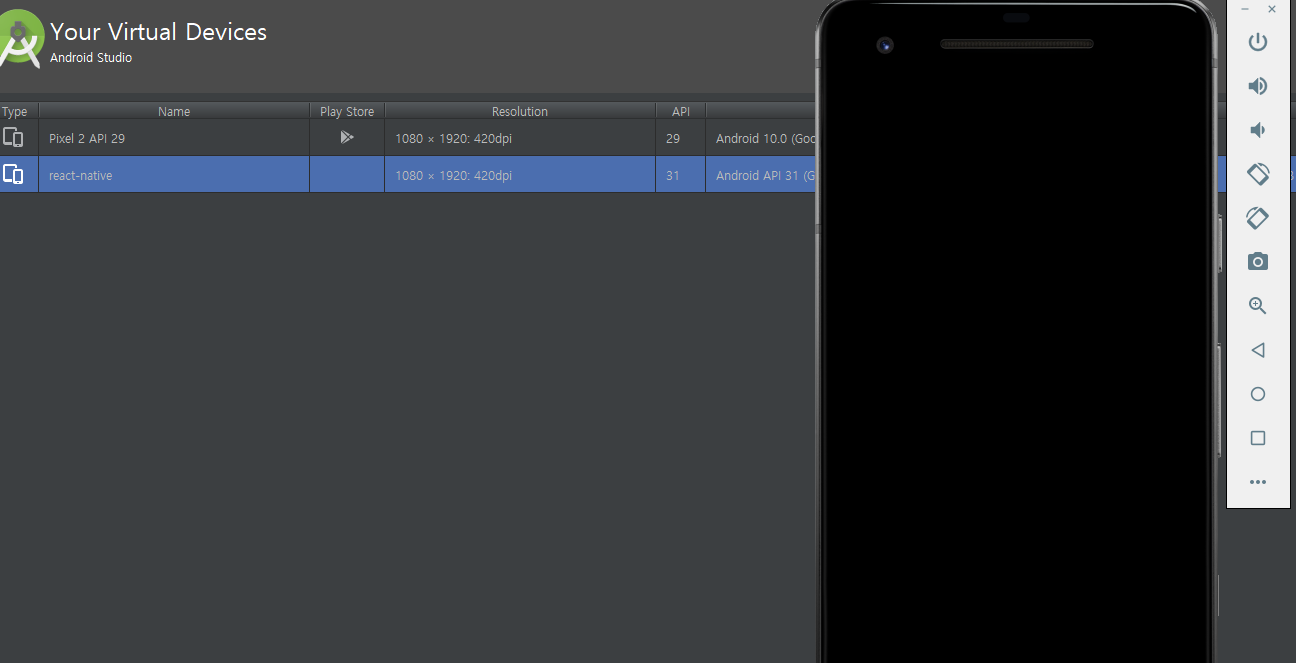
정상적으로 Devices가 설치되면 android 화면을 확인할 수 있습니다. 이제 마지막으로 SDK 경로를 환경 변수에 저장합니다. 기본적으로 SDK 경로를 SDK 설치 시 상단에서 확인이 가능합니다.
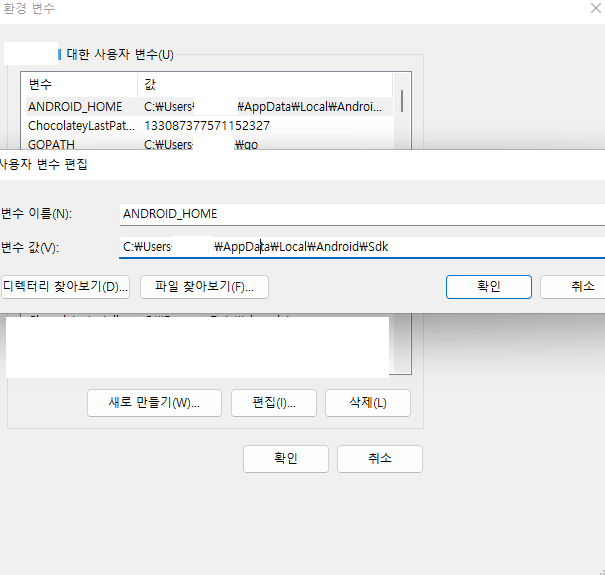
새 사용자 변수를 클릭해서 ANDROID_HOME 변수 이름을 입력하고 변수 값에 SDK 경로를 등록해줍니다.
react-native androd 실행
이제 run-android 명령어를 사용해서 android 버전 react-native를 실행하겠습니다.

생성된 프로젝트 폴더로 이동해서 cmd를 실행합니다.
npx react-native run-android 명령어를 사용하면 실행 화면이 활성화되면서 Android를 구성합니다. 모든 구성이 완료되기까지는 매우 긴 시간이 필요합니다. 상위 버전에서는 Android를 별도 실행하지 않아도 자동으로 android Devices를 실행합니다.
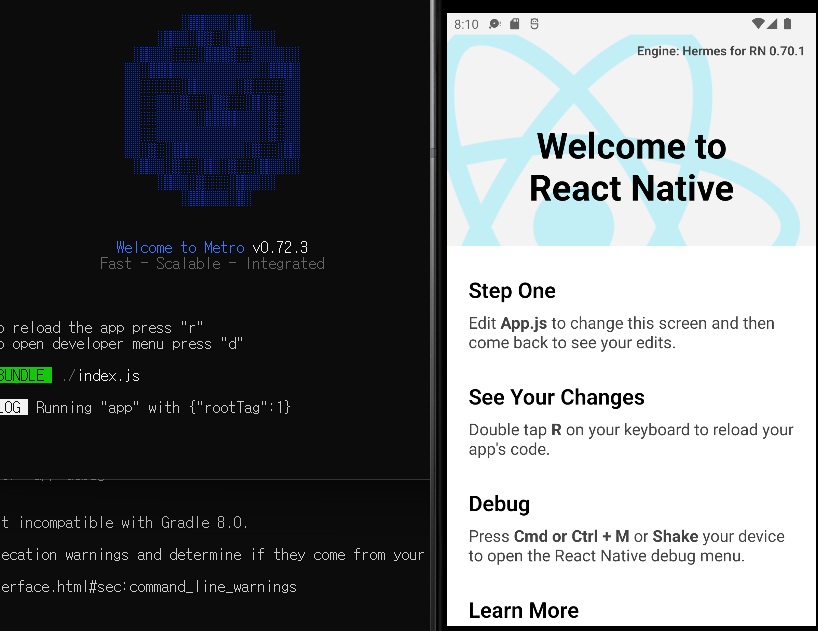
모든 준비가 완료되면 실행된 android 화면에서 "Welcome to React Native" 앱 실행 화면을 확인할 수 있습니다. react native는 많은 설정이 필요하지만, 한번 설치하면 간단하게 업그레이드가 가능합니다. 생산성 높은 앱 개발 언어를 찾고 있다면 react-native Windows에 한번 설치해보세요. 감사합니다.

'IT 나라 > 리액트(React)' 카테고리의 다른 글
| react native Image Component 사용방법 (1) | 2022.10.10 |
|---|---|
| react native Button 생성 및 이벤트 연동 (0) | 2022.10.07 |
| react native error cli.init is not a function 해결 방법 (0) | 2022.09.28 |
| React material-ui 설치 방법 (0) | 2022.04.18 |
| React You are running `create-react-app` 5.0.0, which is behind the latest release (5.0.1) error (0) | 2022.04.15 |